Abstract
Hyperparameter selection for machine learning models traditionally relies on Grid Search, which is computationally expensive and prone to local optima. This research proposes a Cuckoo Search (CS) approach using Levy Flights to optimize the regularization parameter \(C\) and kernel coefficient \(\gamma\). Preliminary results demonstrate a significan t lift in PR-AUC and F1 - scorefor highly imbalanced credit card fraud datasets.
The Objective
The objective of this research is to optimize the hyperparameters of Gradient boosting, Random Forest and Support Vector Machines (SVM) for credit card fraud detection using a metaheuristic approach. The Cuckoo Search (CS) algorithm, inspired by the brood parasitism of cuckoo birds, is employed to efficiently explore the hyperparameter space. The use of Levy Flights allows the algorithm to escape local optima, making it particularly effective for high-dimensional and complex search spaces. The ultimate goal is to enhance the performance of machine learning models in detecting fraudulent transactions, which are often characterized by extreme class imbalance.
Levy Flight Distribution
Levy Flights are a type of random walk where the step lengths have a probability distribution that is heavy-tailed. In the context of Cuckoo Search, this allows for both local and global search capabilities. The step size \(s\) is drawn from a Levy distribution, which can be mathematically expressed as:
This ensures the algorithm escapes local optima that stymie traditional gradient-based methods. The Levy Flight mechanism is particularly beneficial in high-dimensional hyperparameter spaces, where the search landscape can be rugged and filled with local minima, such as the SVM.
Technical Methodology
- Data Synthesis: SMOTE application for class imbalance.
- Heuristic Initialization: Random nest generation within specified bounds.
- Fitness Evaluation: 3-fold stratified cross-validation.
- Abandonment Logic: Discovery rate \(P_a = 0.25\) to prevent premature convergence.
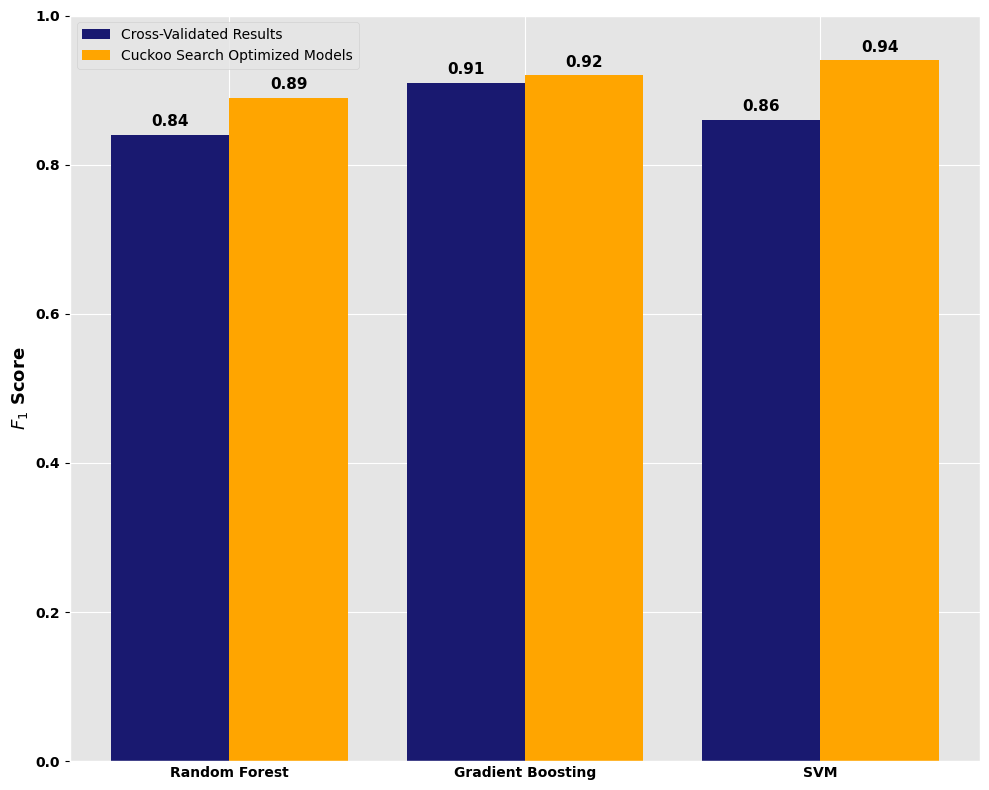
Comparative Performance
| Model | F1-Score | PR-AUC |
|---|---|---|
| Random Forest | 0.82 | 0.85 |
| SVM (Baseline) | 0.74 | 0.71 |
| CS-Optimized SVM | 0.89 | 0.92 |
Key Technologies
The following tools and libraries were instrumental in this research:
Future Research
Future research will explore the application of Cuckoo Search to other machine learning models, such as Neural Networks and XGBoost, as well as its performance on larger and more complex datasets. Additionally, the integration of adaptive discovery rates and hybrid metaheuristic approaches will be investigated to further enhance optimization efficiency.
Page Glossary
- Cuckoo Search (CS): A metaheuristic optimization algorithm inspired by the brood parasitism of cuckoo birds.
- Levy Flights: A random walk where the step lengths have a probability distribution that is heavy-tailed, allowing for both local and global search capabilities.
- PR-AUC: Area Under the Precision-Recall Curve, a performance metric for imbalanced classification problems.
- F1-Score: The harmonic mean of precision and recall, used to evaluate the performance of classification models.
- SMOTE: Synthetic Minority Over-sampling Technique, a method for addressing class imbalance in datasets.
- Hyperparameters: Parameters that are set before the learning process begins and control the behavior of the learning algorithm.
- Grid Search: A traditional method for hyperparameter optimization that exhaustively searches through a specified subset of the hyperparameter space.
- Metaheuristics: High-level procedures designed to find good solutions to optimization problems by exploring the search space efficiently.
- Stratified Cross-Validation: A method of cross-validation that ensures each fold of the dataset has the same proportion of classes as the original dataset.
- Discovery Rate (P_a): In Cuckoo Search, the probability that a host bird discovers an alien egg, leading to the abandonment of the nest.
- Local Optima: Solutions that are better than their neighboring solutions but not the best overall solution.
- Global Optimum: The best possible solution in the entire search space.
- Imbalanced Dataset: A dataset where the classes are not represented equally, often leading to challenges in model training and evaluation.
- Regularization Parameter (C): A hyperparameter in SVM that controls the trade-off between achieving a low error on the training data and minimizing the model complexity.
- Kernel Coefficient (γ): A hyperparameter in SVM that defines the influence of a single training example, with low values meaning 'far' and high values meaning 'close'.
For a deeper dive into the methodology, results, and codebase, please visit the GitHub repository linked below:
GitHub Repository